昨天我們認識了「空氣品質指標AQI」資料集,今天要正式開始讀取資料並挑選出分析所需的欄位。由於原始資料欄位非常多,若全部使用會讓後續分析過於雜亂,因此我們會先挑選出核心欄位:縣市(county)、空氣品質指標(AQI)、PM2.5、時間(publishtime)。這樣能確保後續做趨勢分析或縣市比較時更加清晰。
程式實作
首先,我們先用pandas讀取CSV檔,並把時間轉換成Python可以理解的日期格式:
import pandas as pd
# 讀取空氣品質資料
df = pd.read_csv("IT_AQI/AQI.csv")
# 篩選出主要欄位
df = df[["county", "aqi", "pm2.5", "publishtime"]]
# 將時間欄位轉換為 datetime 格式
df["publishtime"] = pd.to_datetime(df["publishtime"])
# 檢視前 5 筆資料
print(df.head())
print(df.info())
執行後,我們會看到類似這樣的輸出: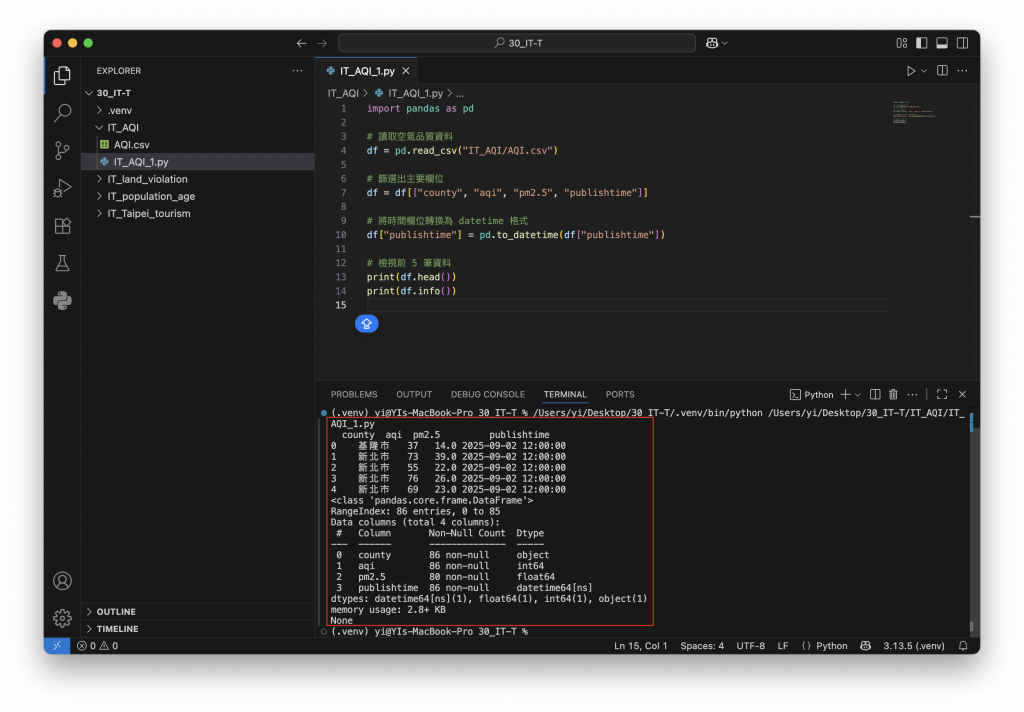
在這裡我們完成了第一步「資料清理」。因為這份AQI資料的時間粒度細(通常是逐小時),後續如果要做「年度趨勢」或「縣市平均」就需要額外做時間聚合。接下來我們會進一步比較不同縣市的平均AQI排行,看看哪個縣市的空氣品質長期較佳,哪個縣市需要特別關注。


 iThome鐵人賽
iThome鐵人賽